收集現場數據的高通量技術使得在生命科學的幾個分支進行大規模觀測成為可能。收集的數據范圍可以從分子水平(基因型)到生理(表型特征)和環境觀察(例如天氣、土壤條件)。這些大量的數據被統稱為表型學數據,代表了潛在生物系統動力學的關鍵科學知識的寶庫。然而,由于這些復雜數據集的多維性和對其復雜結構的先驗知識的缺乏,從這些復雜的數據集中提取信息和見解仍然是一項重大挑戰。
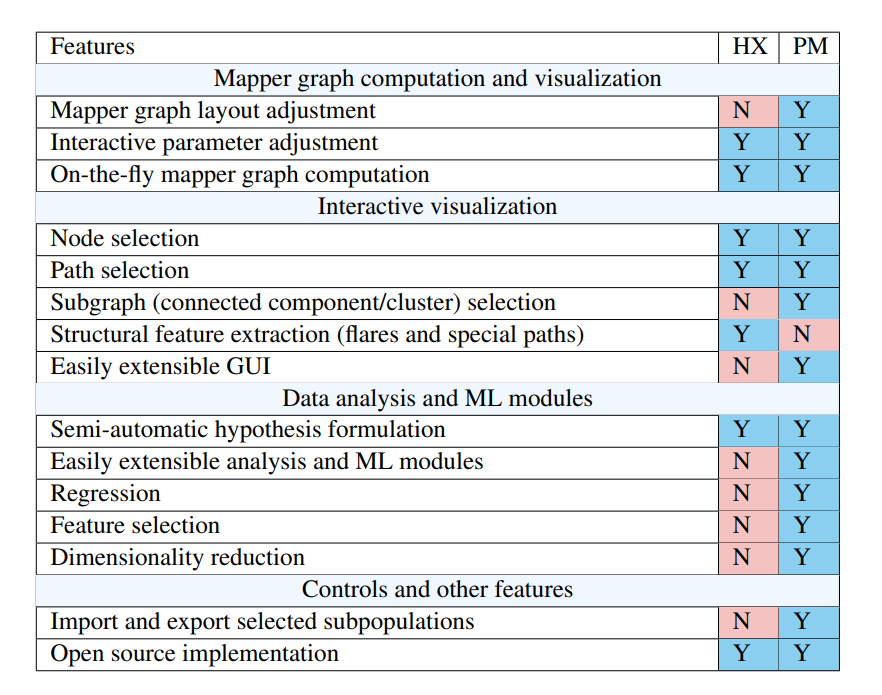
比較Hippo-X(HX)與Pheno Mapper的特征。藍色表示“是”(Y),粉紅色表示“不”(N)。
在本文中,作者介紹了Pheno-Mapper,一個用于探索性分析和可視化大規模現象數據的交互式工具箱。作者的方法是使用mapper框架對數據進行拓撲分析,然后使用內置的數據分析和機器學習功能呈現可視化表示。作者在真實的植物(如玉米)現象數據集上演示了這一新工具的實用性。
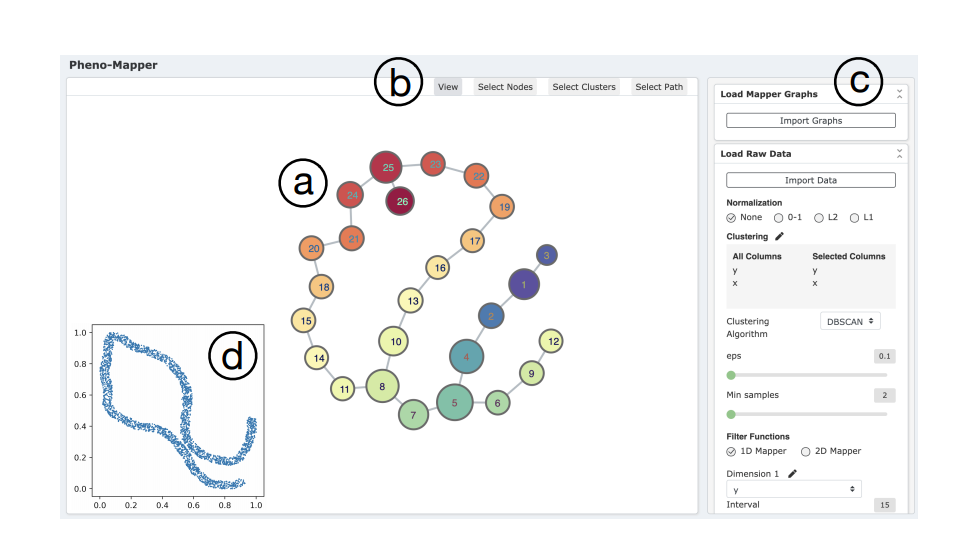
Pheno-Mapper 的用戶界面
與現有方法相比,Pheno-Mapper的主要優勢在于它提供了豐富的、交互式的對物候數據進行探索性分析的能力,并且它以一種易于擴展的方式將可視化分析與數據分析和機器學習相結合。特別是,Pheno-Mapper允許在數據拓撲總結的指導下進行子種群的交互選擇,并將數據挖掘和機器學習應用于這些選定的子種群進行深入探索。
來源:Pheno-Mapper: An Interactive Toolbox for the Visual Explorationof Phenomics Data.
Youjia Zhou,Methun Kamruzzaman,Patrick Schnable,Bala Krishnamoorthy,Ananth Kalyanaraman,Bei Wang
https://arxiv.org/pdf/2106.13397.pdf

 鄂公網安備42018502003245號 網站地圖
鄂公網安備42018502003245號 網站地圖



